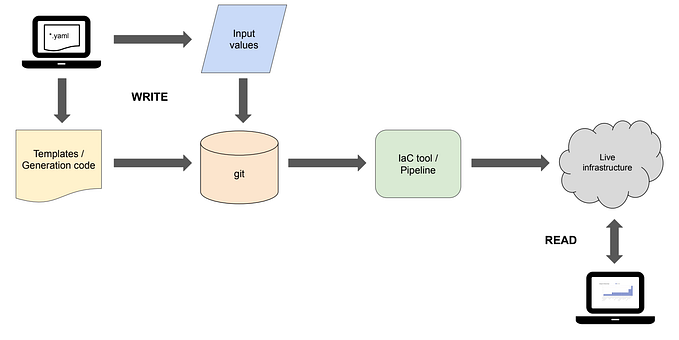
Streamlining Data Solutions Delivery with Centralized Framework
Data-driven enterprises build advanced data processing solutions to extract valuable insights and enable strategic business decision making. The solutions are built using various technologies and tools. In a certain enterprise, it’s possible to see many teams, each of them working in different business units, working on different data. However, they want to build the same data solution using the same technologies and tools, but the difference lies in data, processing, and transformation.
When it comes to delivering these solutions, data teams usually struggle with how to bring their data solutions into the test and production stages. They might attempt to automate the delivery, but they find out it’s challenging, time wasting & efforts consuming. New resources that are skilled in automation are needed to do the job. In this post, we are going to see how designing and implementing a centralized data solution delivery service can resolve this issue and help teams to deliver data solutions in a secure, compliance, effective and efficient manner.
Use-case: Data Solution on Azure
To illustrate the concept, let’s consider a sample data solution that is deployed in a development environment on azure. The tech stack includes Azure Data Factory & Azure Databricks. The source code is hosted on GitHub.

All the components are well-integrated into development environment:
- ADF is connected to GitHub repository. Reference.
- ADF_Publish branch has already been created to host ADF resources necessary for deployment.
- ADF has a linked service to connect to databricks clusters and execute certain notebooks. Reference.
2. Azure Databricks repo is connected to GitHub repository. Reference.
- There must be a repo per environment Reference.
- DBX development repo
- DBX staging repo
- DBX production repo
Development Flow and Automation Complexity

A data engineer starts working on a specific task, including data ingestion, transformation, and loading. He begins by creating new Azure Databricks notebooks to process the data as required. Then, he commits those changes to his feature branch. In ADF, the data engineer creates necessary components such as pipeline definitions, data flows, and linked services. He debugs and validates the pipelines, ensuring correct integration with Azure Databricks and successful processing of the data in the specified databricks cluster. Once the feature is ready, a pull request is being raised against develop (or master) branch, where it’s being reviewed and then merged.
At some point, many features coming from different engineers are merged, and it’s time to deploy all features to the staging environment for testing and validation and then to the production environment.
The data team needs a CI/CD pipeline that deploy the whole solution from development environment to staging/production environment with respecting to the quality & validation gates.

When you first look at the flow above to automate the deployment to the staging environment, it looks quite simple and straightforward!
Well, it’s not! There is a certain level of complexity looking at the technology components that we are using. For example:
- Azure Data Factory: we need to override linked services definitions, global parameters, start or stop certain triggers, triggering pipelines, etc.
- Databricks: deploying notebooks, synchronizing repositories, submitting jobs to clusters, etc.
- Azure SQL Database: build a database project, generate DACPAC, deploy DACPAC, etc.
The Challenge of Multiple Data Engineering Teams
In organizations with multiple data engineering teams working on diverse data solutions, each team must invest significant time, effort, and resources to implement a secure and compliant SDLC process. That means duplication of efforts across semantic versioning, code analysis, artifact management, deployments, environment configuration, test automation, security concerns, Jira integration, and more. Each team is going through similar stages and re-invents the same wheel. Inefficient! See picture below:

Centralized Delivery Service
Instead of having individual teams going through repetitive efforts and complicated automation development cycles, a shared DevOps approach can be established. This centralized method simplifies the entire process, ensuring all teams follow a standardized and efficient way of implementing CI/CD pipelines for delivering data solutions to production. This way, data teams no longer need to struggle with the burden of going deep into complex automation scripts.

Capabilities of the Centralized Service
The centralized service or repository contains all automation workflow components (or Reusable workflows in GitHub Actions) and automation scripts. Everything is parameterized and abstracted! The centralized service should be able to handle any specific or new case. No hard-coded or magic strings. It should be as dynamic as possible. Yes we can enforce and recommend a certain structure, architecture, or guidelines that data teams should follow when developing their solutions or while being onboarded to use the service, however, on the other hand, the service should provide cherry picking features either to consider or to ignore during the CI/CD. It should also allow fine-tuning the whole CI/CD process with variables.
- Note: In GitHub Enterprise, it is possible to have a centralized repository that is either private or internal; however, when choosing private, make sure to configure it to be accessible by other repositories. Reference.
Below is a sample folder structure that represents how it looks like:
.
├── .github
│ └── workflows
│ ├── ci-reusable-version.yaml
│ ├── ci-reusable-artifacts.yaml
│ ├── ci-reusable-scanning.yaml
│ ├── ci-reusable-azure-sql-db-dacpac.yaml
│ ├── cd-reusable-adf-dbx.yaml
│ ├── cd-reusable-dbx-pull-repo.yaml
│ ├── cd-reusable-dbx-deploy-notebooks.yaml
│ ├── cd-reusable-dbx-submit-jobs.yaml
│ ├── cd-reusable-jira.yaml
│ ├── cd-reusable-gh-tagging.yaml
│ ├── cd-reusable-gh-release.yaml
│ └── cd-reusable-azure-sql-db.yaml
└── scripts
├── adf
│ └── deploy.ps1
├── dbx
│ ├── deploy-notebook.ps1
│ ├── submit-job.ps1
│ └── repo-update.ps1
├── jira
│ └── comment.ps1
└── etc
├── your-script1
├── your-script2
└── more-scripts
├── script3
└── script4Here is how a data solution CI/CD pipeline is implemented by leveraging the centralized reusables workflows:
on:
workflow_call:
push:
branches:
- main
jobs:
VERSION:
uses: my-organization/shared-delivery-service-repo/.github/workflows/ci-version.yaml@1.5.6
ARTIFACT:
uses: my-organization/shared-delivery-service-repo/.github/workflows/ci-artifacts.yaml@1.5.6
needs: [VERSION]
with:
RUNS_ON: ubuntu-latest
VERSION: ${{ needs.VERSION.outputs.version }}
MAIN_BRANCH: main
.... # other inputs
secrets:
.... # necessary secrets
CD-DATABRICKS-SYNC:
uses: my-organization/shared-delivery-service-repo/.github/workflows/cd-reusable-dbx-pull-repo.yaml@1.5.6
needs: [ CD-DEPLOY ]
if: github.ref == 'refs/heads/main'
with:
ENV: staging
DATABRICKS_URL: my-databricks-url
DATABRICKS_REPO_PREFIX: my-databricks-repo-prefix
.... # other inputs
secrets:
.... # necessary secrets
CD-DEPLOY-ADF:
uses: my-organization/shared-delivery-service-repo/.github/workflows/cd-deploy-adf.yaml@1.5.6
if: github.ref == 'refs/heads/main'
with:
ENV: staging
ADF_NAME: my-adf-name
.... # other inputs
secrets:
.... # necessary secrets
other-jobs:
.... # other jobsWith just a few lines of code and minimal configuration, we could quickly implement a CI/CD pipeline for a new data solution. The centralized repository coupled with reusable workflows and automation scripts accelerates the implementation.
This approach offers a significant speed boost, sparing data teams from building CI/CD pipelines and automation scripts from scratch. Leveraging predefined workflows and making small customizations ensures seamless integration with compliance and security standards.
The beauty lies in delivering a fully functional CI/CD pipeline with minimal effort. It saves time, allowing data teams to focus on core business problems rather than getting caught up in setup complexities.
Release Process and Versioning Strategy
As the centralized service contains code, it needs its own release process. Changes to workflows or scripts should go through collaboration, quality checks, testing, pull requests, and reviews before being merged to the master branch for release. A new release implies a new version of the centralized service and, of course, a new version of the workflows and scripts. It may bring new parameters, new features, or bug fixes.
When a data solution is being onboarded to this service, it will refer to a specific version of the service by using pinned tags, ensuring stability and avoiding the potential disruption caused by ongoing developments in the master/develop branches. However, a new onboarding might also bring new features or uncover existing bugs. This means continuous improvement and refinement of the service, transforming it into a more robust and effective platform over time.
Conclusion
Leveraging a centralized delivery framework is essential for enterprises that have diverse teams sharing similar tech stack. The complexities behind the technologies, security concerns and compliance requirements necessitate a more streamlined approach. The centralized delivery service with reusable workflows and abstracted automation scripts eliminates redundant efforts across teams. This accelerates delivery and ensures efficiency and compliance throughout the SDLC process.