Why UUID7 is better than UUID4 as clustered index in RDBMS
In the Introduction To Database Indexing Article, We discussed database indexes, Their type, representations, and use cases.
In this article, we will experiment to check which performs better as a clustered index. UUID version 4 vs UUID version 7 or 6. Then we will discuss why that happened.
What is UUID version 4?
UUID, an acronym for Universally Unique Identifier, is a 128-bit identifier represented as a 32-character sequence of letters and numbers separated by dashes, formatted as 8–4–4–4–12. The structure of UUID version 4, such as “123e4567-e89b-12d3-a456–426655440000,” showcases its Hex values, each character ranging from ‘1’ to ‘f’. This unique identifier can be stored in databases either as strings or as 16 bytes. Whether generated completely randomly or through a pseudo-random generator, UUID version 4 maintains its exceptional uniqueness.
A sample of 3.26*10¹⁶ UUIDs has a 99.99% chance of not having any duplicates
you can find detailed calculations in reference #2
What is UUID version 7?
Similar to UUID v4, UUID v7 is a 128-bit identifier represented as a 32-character sequence of letters and numbers, formatted as 8–4–4–4–12. The distinctive feature of UUID v7 lies in its nature as a time-ordered UUID, encoding a Unix timestamp with millisecond precision in the most significant 48 bits. In alignment with UUID formats, 4 bits designate the UUID version, and 2 bits denote the variant. The remaining 74 bits are generated randomly, contributing to the uniqueness of this identifier.

Why UUID instead of sequential ID?
Let’s outline the pros and cons of UUIDs compared to sequential IDs:
- Pros:
1. Low Collision Probability: Due to its structure, UUIDs have a very low probability of collision, allowing servers to generate IDs for records before insertion.
2. Suitable for Distributed Systems: UUIDs are well-suited for distributed databases and systems, as they can be generated on servers independently.
3. Enhanced Security: UUIDs contribute to database security by keeping records anonymous, preventing users (or malicious entities) from deducing information about the order of record creation. - Cons:
1. Increased Storage: UUIDs occupy more storage space (16 bytes) compared to traditional IDs (e.g., 4 bytes for INT or 8 bytes for BIGINT).
2. Difficulty in Manual Data Entry: The complexity of UUIDs can make manual data entry challenging.
3. Reduced Query Performance: Larger UUID sizes lead to reduced query performance, as the increased record size results in fewer records stored per database page, leading to more I/O operations and decreased overall performance.
4. Index and Data Fragmentation: UUIDs can contribute to index and data fragmentation, impacting database efficiency. Further discussion on this point is warranted.
Let's start our experiment
Overview:
For this experiment, I am using MySQL, Docker, Node, and Go.
I have created a docker-compose file that runs and configures MySQL and saves data to volume (I clean this volume automatically after the experiment).
Note: It’s worth noting that MySQL was chosen for its default use of clustered indexing for primary keys, a feature absent in PostgreSQL
I will test insertion performance by inserting 1 Million records one by one (if we use bulk the DB engine will sort the records and ruin the experiment) using node.js script and Go. I will simulate multiple servers connecting to one DB using Go and goroutines to insert 2 million records. Running 7 threads one per core. One core will be left to run the docker demon.
In the experiment I simulated a chat Database I have only one Table called “chat_messages” that has columns id, chat_id, sender_id, message, and created_at
the types of id, chat_id, and sender_id will vary from INT to BINARY(16) depending on the data I put either Integer or UUID v4 or UUID v7.


Notes:
- I am measuring the insertion time at the application level. I know this is not the most accurate way and maybe can be done using trigger or stored procedure but this way was faster I repeated the experiment more than once and on different machines and programs (node and go) and the results are similar.
- It’s noteworthy that the experiment was conducted on a dedicated machine, ensuring that the system’s resources were not concurrently utilized during the experimentation process. This deliberate isolation enhances the reliability of the results by minimizing external factors that could potentially impact the measured insertion time.
Steps:
Here is the pseudo-code as the top view of the experiment:
- Run the docker-compose file.
- Connect to the database.
- Create chat_messages table. (UUID v4)
- Insert records and get time. (sum of every insertion) (UUID v4)
- Stop docker & delete volume (Very important to avoid affecting UUID v7 insertions)
- then wait 1 sec. (just to let the system clean memory and swap).
- Create chat_messages table. (UUID v7)
- Insert records and get time. (UUID v7)
- Stop docker & delete the volume.
- then wait 1 sec.
- Create chat_messages table. (Integer)
- Insert records and get time. (Integer)
- Stop docker & delete the volume.
- then wait 1 sec.
If you want you can clone this repo and run the experiment on your machine.
Results:
Node process inserting 1 Million records:
UUIDV4: 24345338.406382076
UUIDV7: 23579840.35688359
INT: 23678315.194741927
UUID V4 / UUID V7 persentage: 1.0324640895745087
Here as well, we can see that UUID v4 took 3% more time than UUID v7
GoLang process inserting 1 Million records:
UUIDV4: 2.6320770985406373e+07
UUIDV7: 2.5592608053863425e+07
INT: 2.5759889825318027e+07
UUID V4 / UUID V7 percentage: 1.0284520799916297
Here as well, we can see that UUID v4 took 3% more time than UUID v7
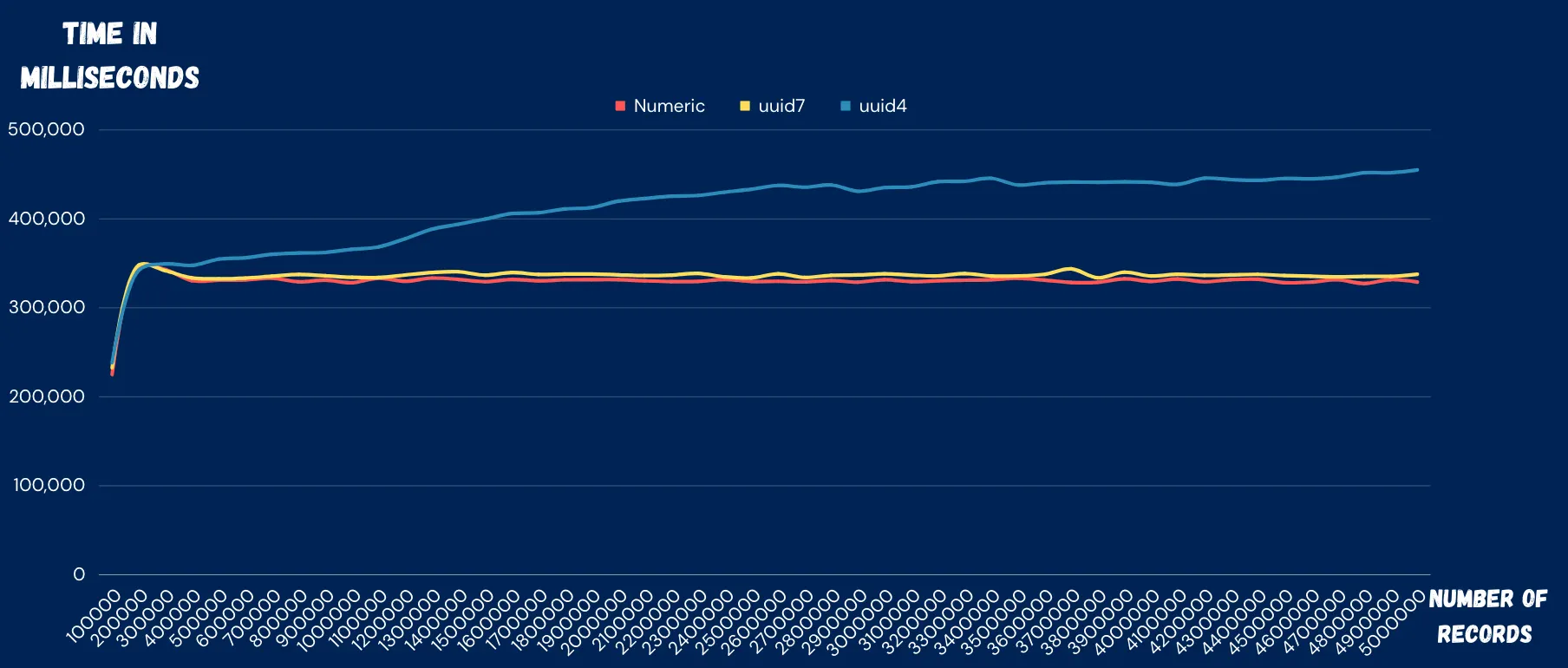
MultiThreaded Go Program inserting 5 Million records with 7 threads:
I have 8 cores so I tried to make every thread stick to one core.
UUID V4: 20634873.5100111 millisecond
UUID V7: 16750775.02223781 millisecond
INT: 164567295.36401817 millisecond
UUID V4 / UUID V7 percentage: 1.2318757479947573
Here we can see that UUID v4 took ~23.1% more time than UUID v7
and 25.3% more than Integer. (Please note that the result may vary from one run to another)
Why UUID v7 was faster than UUID v4?
Index locality:
To establish a shared understanding, let’s revisit the concept of a clustered index as previously outlined in the referenced article. The storage mechanism for a clustered index is pivotal for understanding the results.
How is the clustered index stored?
We mentioned that each data piece is stored on a page. Indexes, in turn, are stored as b+ trees within a page. This implies that the keys within the indexes are sorted. Consequently, any insertion of a new key between two existing keys necessitates the reorganization of stored indexes. This reorganization process may involve fetching multiple pages, reading those pages, and inserting a new page while adjusting the next and previous pointers (rather than splitting pages).


Notice the addition of 15 to the root page. Figure 4 After introducing the record with ID 8, the page containing 10, 15, and 20 is split in. It’s important to note that the Data page is also split during this process.

With that said you now can guess you can guess how unordered IDs can hinder the performance.
UUID v4 IDs lack correlation with one another, as they exhibit poor index locality due to their completely random nature. Consequently, a newly generated UUID v4 may have a Hex value less than an older one. Given that we are utilizing a clustered index, it is necessary to position the newly generated UUID v4 before the previous one to maintain the desired order.
Unlike UUID v7, they are inherently sorted Due to their time-based nature. That generates that values are almost sequential, consistently inserted at the end of the last page (if all the servers are in sync). This characteristic effectively eliminates the index locality problem.
Buffer Pool:
If this concept is new to you let me quickly introduce it to you.
The Database engine as any other running process on our machines doesn’t have infinite memory. They request memory of fixed size from the OS. The Database engine is used to do multiple things like query optimization, parsing records, sorting records, joining records anything else. But most importantly for us, there is a part of this memory location to keep the read pages from the storage as well as to create new pages to insert new records this memory partition is called a “Buffer Pool”.
Its use is not limited to storing pages from read (select) operations. it is used also for inserting, update, and deleting. The Database engine should fetch the page in which the target record is live or would be inserted, then insert it, update it, or delete it.

How is this related to our problem?
It is the core of the UUID v4 bottleneck. the problem is that the IDs are very random and the buffer pool is getting filled up quickly every record can be on a different page so the Database engine will go and fetch it and if the buffer pool is full it should write a page or more back to disk to free up some spaces and the very next record may or may not be in the same page that w just written and this loop will keep going.
However, that doesn’t happen in the case of UUID v7 or Serial Integer because the records’ IDs are granted to be in increasing order. So records will be added to the last page when we reach the page limit. the database engine will create a new page, Maybe it will right the old page to the disk or it may wait for the Buffer pool to be filled and only write to the WAL.
The last question is Why Serial was faster than UUID?
That is a very easy-to-answer question now. if you recall every record in Database is inserted in a page and pages are of fixed size by default 16 KByte (MySQL) and 8 KByte (PostgreSQL) the size of the record in case of INT ID is equal to 271 Byte (4 + 4 + 4 + 255 + 4)(INT, INT, INT, VARCHAR(255), TIMES…). However, the record in the case of UUID is 307 (16 + 16 +16 + 255 + 4).
That is 6 more records per page if we assume that the page only contains a record (which is not, but the ratio may be the same or worse, I don’t know). But the page containing records with INT ID will have more records, which means less IO and more speed.
One small note that the Idea of adding timestamp GUID is not new, UUID v1 did it (but it had its drawbacks), Instagram’s ShardingID, Shopify used ULID instead of UUID v4, and MongoDB ObjectID does something similar.
Finally, I hope you enjoyed this article and learned something new. Please let me know if you find enhancement can be done.
Future work:
- I would like to Test it with Rust.
- Get the Size of the Index B+ tree for every Index Type.
- Use a pool of database connections instead of just one connection.
